Important: Disclaimer
This is not the official site but a set of brief descriptions of our recent work to support transparency and collaboration. For more information about NHS England please visit our official website
How to Assess the Privacy of Unstructured Data
“What are the privacy considerations that need to be addressed when dealing with unstructured healthcare text data “
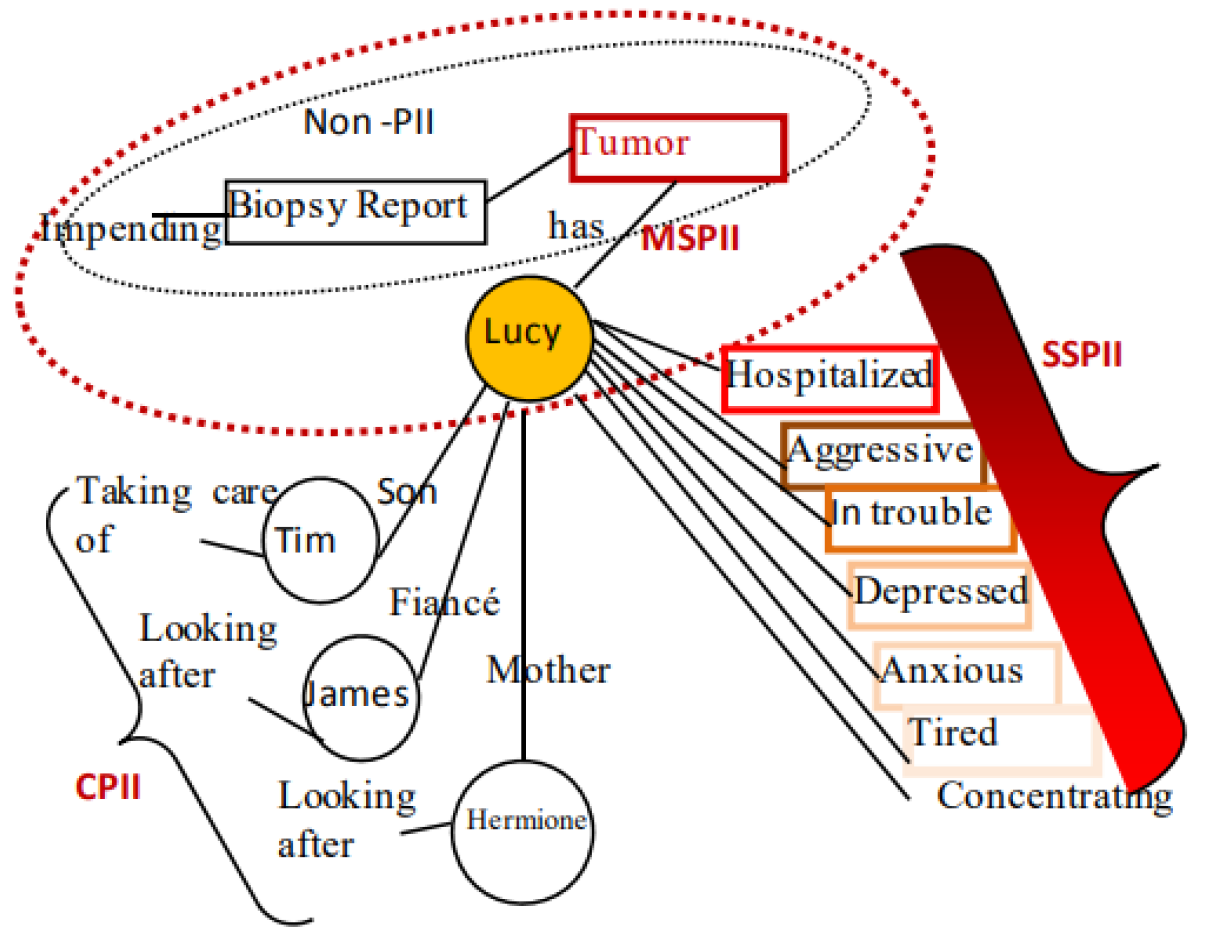
Figure 1: Figure 4 from Al-Fedaghi, Sabah. (2012). Experimentation with Personal Identifiable Information. Showing an example PII sphere from different perspectives (compund, singleton and multitude personal identifiable information)
Unstructured data (e.g. text, image, audio) makes up a significant quantity of NHS data but is comparatively underused as an evidence source for analysis. This is often due to the privacy concerns restricting the sharing and use of these data.
To our knowledge, there are currently no tools on the market that allows the NHS to robustly ascertain the level of privacy of unstructured data. To have confidence when commissioning tooling for anonymisation purposes the NHS needs an understanding of what private content, health related text data can contain. The tooling put in place to protect the privacy of these data needs to be able to assess the content, evaluate the risk associated with the content, and demonstrate that the tooling functionality has dealt with any privacy concerns appropriately.
During this time the three main activities were a literature review, bringing a range of expert and voices together into a workshop, and writing the associated report summarising our understanding of the problem.
Results
The main output specified was for a list of key qualities that could feed a tool specification in the future. The qualities the report highlighted were:
Structuring and data handling
- Ability to flag and identify with the range of possible data issues prior to deidentification (misspellings, medical terms, acronyms)
- Connection with a clinical vocabulary in order to match and assist word identification to assist structuring of the data.
- Ability to flag the data variables required for anonymisation to assist in the risk analysis and disclosure control process
- Ability to deal with unstructured, semi-structured and structured data
- Ability to deal with different formats of free-text data e.g. medical notes, patient feedback, survey responses, research papers
Tool Use & Validation
- Ease of manual manipulation in order to react to the level of anonymisation required and the key variables to be maintained for data utility
- Automated auditing of the flagged terms, any data manipulation and tool manipulation that has taken place
- Ability to demonstrate quality and anonymisation level before and after each stage of the de-identification process for the QC process.
- Ability to apply manual QC at each step along the process QC (human and automated) or the requirement of human authorisation to move to the next step
- Clarity around the tool limitations
- Need to align with the Information Governance (IG) process
Context
- Ability to tune into a domain extracting and utilising the appropriate medical dictionary. b. Clarity around individual versus population
- Ability to define level of anonymisation
Flexibility
- Ability to adapt the anonymisation functionality to the risk level assessed
- Flexibility within the tool programming to adapt to the utility required and hence the purpose of the output data aligning the appropriate level of de-identification
- Incorporated regular updating and reaction to current “threats”
| Output | Link |
|---|---|
| Open Source Code & Documentation | n/a |
| Case Study | Awaiting Sign-Off |
| Technical report | Here |