Important: Disclaimer
This is not the official site but a set of brief descriptions of our recent work to support transparency and collaboration. For more information about NHS England please visit our official website
Investigating Applying and Evaulating a Language Model to Patient Safety Data
“What’s the most suitable models and workflows for represneting an NHS text dataset?”
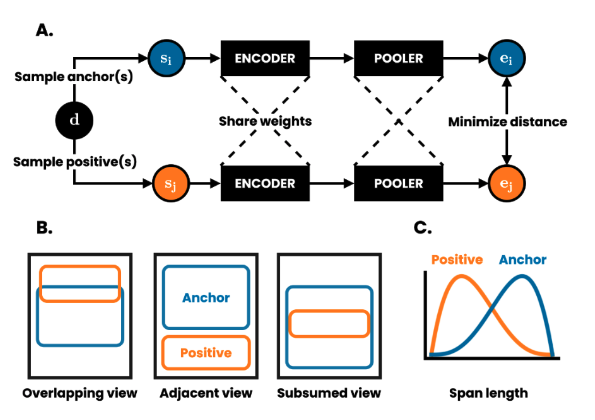
Figure 1: Taken from DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations - arXiv:2006.03659
In collaboration with the NHS England patient safety data team, we present an exploration of a selection of different language model pretraining and finetuning objectives with patient safety incident reports as the domain of interest, followed by a discussion of a number of methods for probing and evaluating these new models, and their respective embedding spaces.
Results
Results showed that the models trained on the patient safety incident reports using either the Masked Language Model (MLM) objective, or the MLM plus contrastive loss objective, appeared to have a superior performance on the presented pseudo-tasks when compared to their general domain equivalent. Whilst the performance in the frozen setting did not match that of the full fine-tuned setting, we have not performed a thorough investigation, for instance we could look to utilising larger base models. Further there are other examples of promising approaches which can better utilise frozen language models at scale, such as prompt learning and parameter efficient fine-tuning.
| Output | Link |
|---|---|
| Open Source Code & Documentation | Github |
| Case Study | Awaiting Sign-Off |
| Technical report | Here |