Important: Disclaimer
This is not the official site but a set of brief descriptions of our recent work to support transparency and collaboration. For more information about NHS England please visit our official website
TxtRayAlign
“Generating descriptive text from X-Ray images using contrastive learning on multi-modal data”
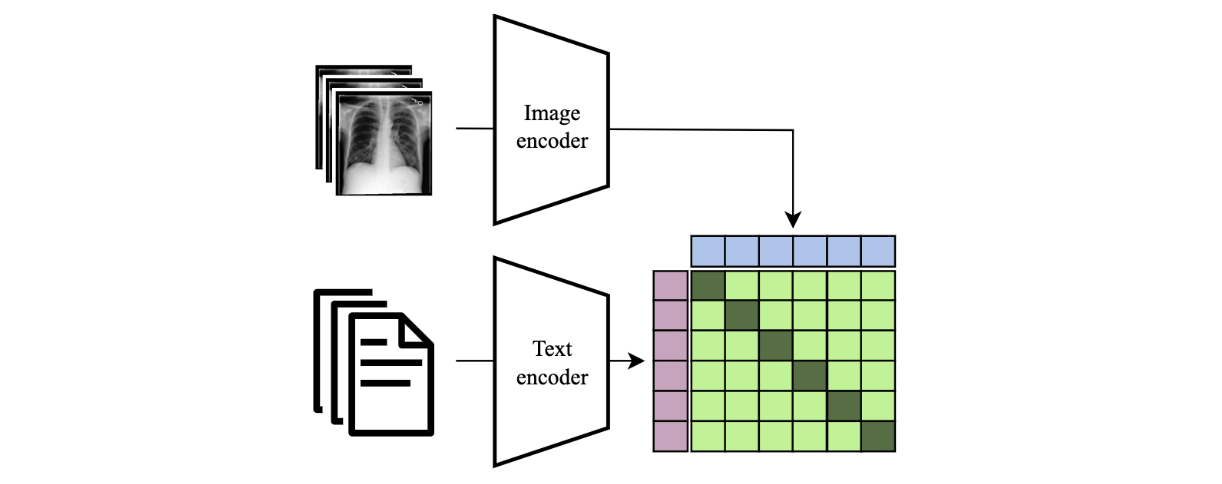
Figure 1: A contrastive retrieval mechanism. A query image is encoded and compared with the embeddings of a corpus of reference reports. The report with the greatest cosine similarity in the shared embedding space is returned as the output.
TxtRayAlign exploits contrastive training to learn similarities between text and images, allowing a retrieval-based mechanism to find reports that are “similar” to an image.
Results
We observe that even the best performing model (ResNet50-DeCLUTR) only retrieves anything of relevance for 62% of queries. The retrieved sentences tend to contain findings that are not relevant for the query, as indicated by the relatively poor precision. Further, the query image contains findings that are only poorly covered by the retrieved sentences, as indicated by the low recall.
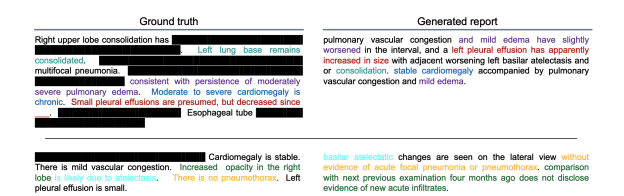
Figure 2: Two example reports generated by ResNet50-DeCLUTR (trained on 5%). Highlighted text corresponds to matches of the CheXpert sentence label between the ground truth and generated report. Ground truth report partially redacted for privacy.
The results of our investigation indicate that this approach can help generate reasonably grammatical and clinically meaningful sentences, yet falls short in achieving this with sufficient accuracy. While improvements to the model could be made, our findings are corroborated by others in literature. Besides improving performance, future work could develop other applications of TxtRayAlign for other downstream tasks, such as image-to-image or text-to-image retrieval.
| Output | Link |
|---|---|
| Open Source Code & Documentation | Github |
| Case Study | Awaiting Sign-Off |
| Technical report | Here |